Synthetic biology is no longer a niche research discipline. It is becoming a core industrial capability, and it is scaling at a pace that is exposing deep structural weaknesses in how biological work is tracked, governed, and reused.
Today, more than 12,000 organisations worldwide are actively engineering biological systems, spanning pharmaceuticals, chemicals, materials, food, agriculture, energy, and environmental applications. That number continues to grow as tools for writing DNA become cheaper and more accessible, and as engineered biology moves from research into production and deployment. The economic stakes are rising just as fast. Industry forecasts project the synthetic biology economy to reach approximately $80 billion by the mid‑2030s, driven by the industrialisation of biological design and the expansion of engineered organisms into real‑world supply chains. Yet beneath this rapid growth lies a less visible problem.
Across organisations, teams are losing up to £150,000–£2 million per year to inefficiencies caused by repeated experiments, fragmented data, frozen biological assets, and unprovable intellectual property. These losses are not the result of failed science. They stem from missing provenance, broken lineage, and the inability to reliably answer a basic question: what biological thing produced this result, and how did it come to exist?
Perhaps most telling is what happens to the outputs of all this work. Internal industry analysis shows that over 90% of engineered biological assets are never reused or commercialised. They remain locked in freezers — not because they lack value, but because their identity, history, and ownership cannot be trusted well enough to reuse, share, or scale them safely.
This is the SynBio Data Tax: the compounding cost of engineering living systems without the infrastructure required to track change over time.
It shows up as duplicated effort at the bench, as stalled collaborations, as delayed regulatory pathways, and as AI initiatives that fail before they start because training data lacks verified lineage. It is paid quietly, repeatedly, and almost universally — by startups and multinationals alike.
As synthetic biology continues to scale, this tax will only grow unless the industry addresses its root cause.
The symptoms are well known and widely reported
For decades, researchers have documented widespread cell line misidentification, where biological materials are not what they are believed to be.

Studies estimate that a significant fraction of published work relies on misidentified or contaminated cell lines, and these errors continue to propagate through the literature. Researchers are routinely urged to resequence shared plasmids to confirm what they have received and check that strains ordered from culture collections have not been mislabeled or subject to reversion or drift. Surveys repeatedly report that a majority of scientists struggle to reproduce published results (RDWorld online).
These are often framed as failures of training, documentation, or scientific rigour. But that diagnosis misses the deeper pattern. Across cell lines, plasmids, and engineered strains, the same assumption keeps breaking down: that biological identity is stable once we name it.
Living systems do not behave that way as Beatrix Ellis, CEO of GitLife explains: “Living systems drift under selection and accumulate changes as they are handled, stored, shared, and reused. If you cannot confidently share a cell line or prove its identity: failure arrives quietly and causes all sorts of problems.”
This is the infrastructure problem which GitLife Biotech is focused on solving.
Over the years, industry has tried to address these failures by marketing more tools to labs: electronic lab notebooks (ELNs), laboratory management information systems (LIMS), stricter standard operating procedures (SOPs), better file storage, and more compliance checks.
These tools are helpful to a certain degree, but they do not solve the core issue.
Most laboratory systems are designed to store states but they don’t track change over time. They capture:
- snapshots of data;
- documents;
- and results
But they rarely capture how one state became another, who made which change, and why. Files get overwritten. Context gets lost. Lineage fragments across systems.
As a result, when something goes wrong, teams are forced into forensic reconstruction: piecing together histories from filenames, emails, notebooks, and institutional memory. This approach collapses under scale.
This problem is not unique to biology. Software engineering faced the same challenge decades ago. As codebases grew increasingly more complex and collaborative, it became impossible to rely on care, discipline, or documentation alone. The solution was not “better programmers”, it was version control in the form of git, GitHub and GitLab.
Version control systems treat change itself as data. Every modification is recorded as a first‑class object, with authorship, timestamp, intent, and context. Parallel ideas can be explored safely through branching. Successful paths can be merged. Differences between versions can be examined precisely. Crucially, nothing is silently overwritten.
Version control is not storage or backup. It is tracked change with memory. It answers what changed when, by who and why.
What version control means for synthetic biology
Applying this idea to synthetic biology requires a shift in mindset.
In a biological context:
- A repository represents an engineering programme: an organism, workflow, dataset, its goals, and its associated data.
- A branch represents a hypothesis path: alternative edits, optimisations, or design strategies explored in parallel.
- A commit represents a milestone snapshot: genotype, phenotype, protocols, data, and authorship captured together as a coherent state.
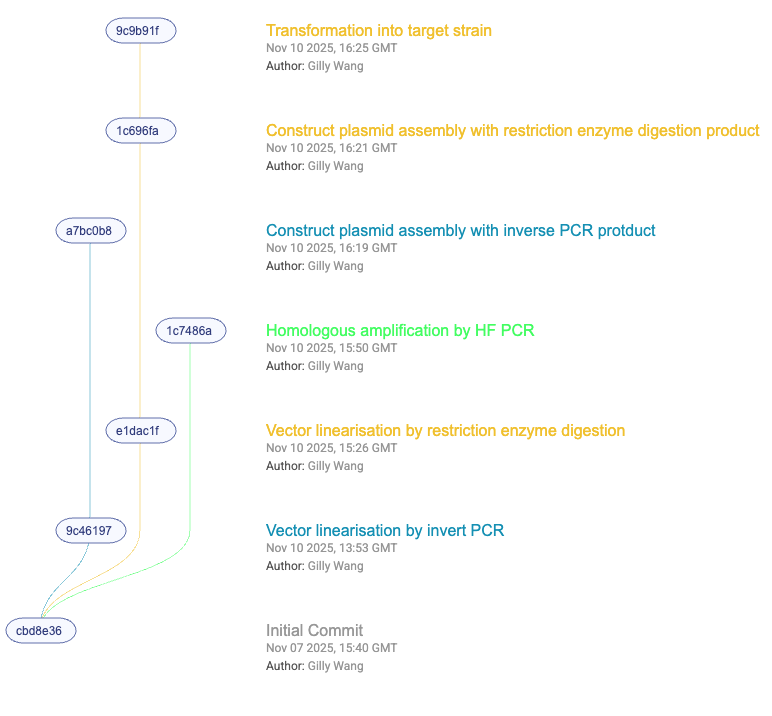
Figure – In CellRepo, Gitlife Version control software, every experiment & dataset has immutable time and author-stamped lineage
This is not file versioning. It is the structured capture of engineering history, the ability to understand not just what a biological system is, but how it became that way.
When biological work is version‑controlled and physically linked to its history, several capabilities emerge that are difficult or impossible today:
- Reproducibility improves because results can be tied to specific versions, not vague strain names.
- Auditability becomes practical through immutable commit histories with authorship and intent.
- Reuse becomes safer because assets carry verified lineage and chain‑of‑custody.
- Collaboration and sharing become less risky because identity and ownership are provable.
- AI and automation become more viable because training data is clean, structured, and lineage‑linked.
This is not about adding another tool to an already crowded stack. CellRepo introduces the missing infrastructure layer that allows all other tools to work together coherently.
Without version control, the SynBio Data Tax continues to compound, quietly eroding trust, value, and scalability. With it, biology begins to behave like a mature engineering discipline: accountable, reusable, and governable.
GitLife’s version control platform for biology
GitLife is building a version‑control platform for applied biological R&D, designed to make strain development work reusable, auditable, and AI‑ready. The platform structures digital R&D history using commits, branches, and lineage (similar to GitHub) and, where it matters, anchors key biological states back to that history using embedded DNA barcodes, creating a verifiable link between the physical strain and its digital record.
Our Software platform is now live and we’d love for people to take a look. https://www.cellrepo.com/
CellRepo is our cloud-based platform that brings true version control, traceability, and collaboration to engineered biology.
Here are a few things worth checking out:
- Documentation: Clear, step‑by‑step guides to get started, including how to create organisations, projects and repositories and how to start recording commits, https://docs.cellrepo.com/
- Examples: A set of demo repositories showing how version-controlled biology works in practice — great for getting an intuitive feel for the workflow. Search for “demo” in the Explore tab
If you’d like a walkthrough or want to explore how this could fit into your work, you can book a demo through the platform.